The Frontier Model Market Just Restructured Overnight: What Gemini 2.5 Pro Deep Think, Fable 5's Billing Cliff and the OpenRouter Fusion Data Mean for Every Enterprise AI Architecture
Three things happened in the enterprise AI model market simultaneously on June 23, 2026. Google launched Gemini 2.5 Pro Deep Think with a 2-million-token context window at $15/$60 per million tokens. Fable 5's free trial window expired, moving to usage credits at $10/$50 — double the cost of Claude Opus 4.8. And OpenRouter published DRACO benchmark results showing a budget panel of Gemini 3 Flash, Kimi K2.6 and DeepSeek V4 Pro scoring within one point of Fable 5 alone at roughly half the cost of any single frontier model. Every enterprise AI architecture that has not yet incorporated both realities is working from a market map that expired overnight.
Date
Jun 23, 2026
Category
Technology
Reading Time
7 minutes
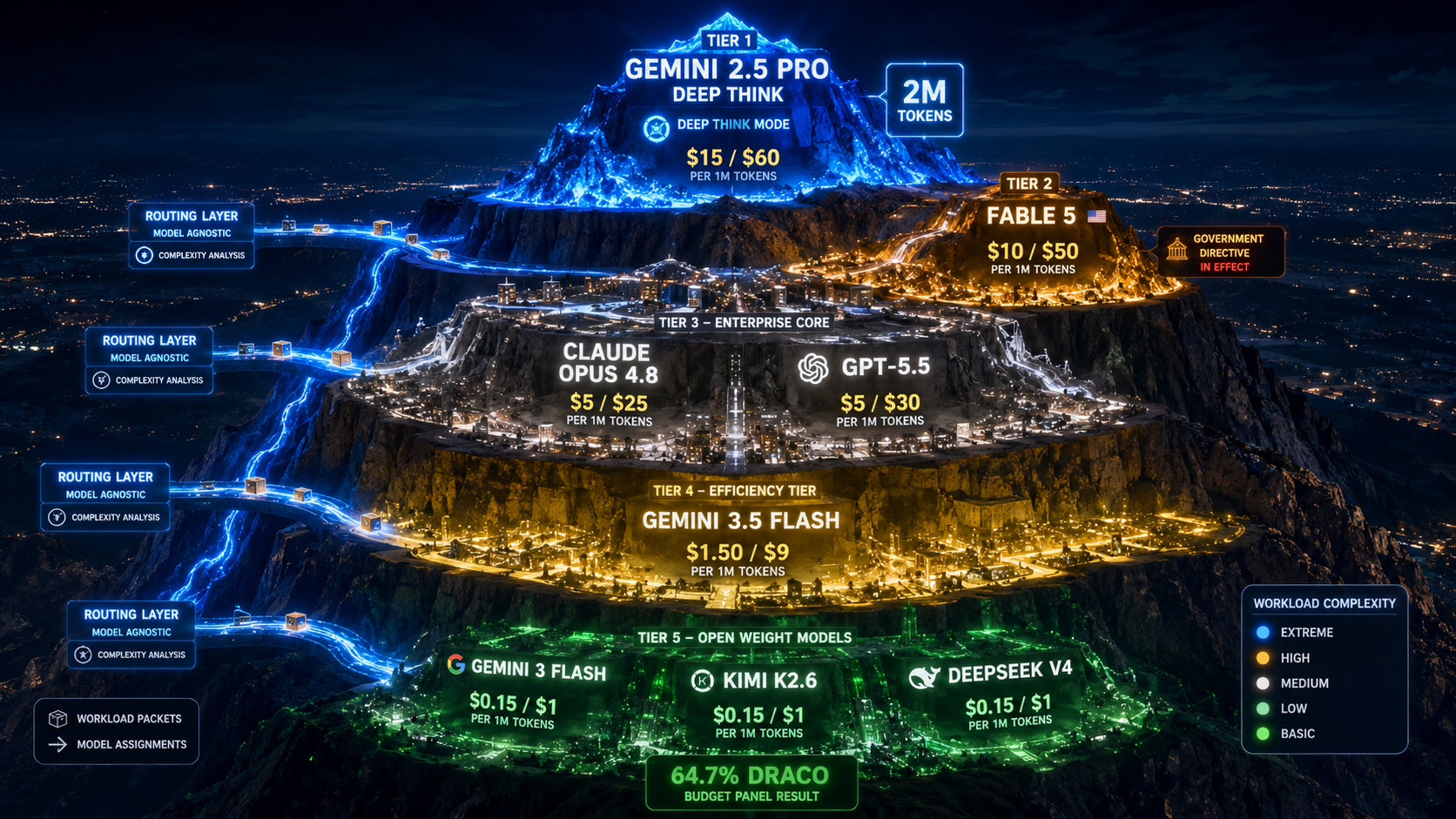
Three things happened in the enterprise AI model market simultaneously on June 23, 2026. Google launched Gemini 2.5 Pro Deep Think — its most capable model to date, available on the API, AI Studio and Vertex AI, with a 2-million-token context window, a dedicated Deep Think mode for hard multi-step reasoning, and pricing at $15 per million input tokens and $60 per million output tokens. At midnight, the Fable 5 free trial window that Anthropic announced on June 9 expired — starting today, Fable 5 requires usage credits at $10/$50 per million tokens, double the cost of Claude Opus 4.8. And OpenRouter published DRACO benchmark results showing that its Fusion multi-model synthesis tool produced a budget panel combining Gemini 3 Flash, Kimi K2.6 and DeepSeek V4 Pro that scored 64.7 percent — within one percentage point of Fable 5 alone at 65.3 percent — at roughly half the cost of any single frontier model. Three events, one morning, one message: the frontier model pricing tier has just expanded upward and the multi-model efficiency architecture has just become empirically validated. Every enterprise AI architecture that has not yet incorporated both realities is working from a market map that expired overnight.
Gemini 2.5 Pro Deep Think launched on June 22-23, 2026, available on the API, Google AI Studio and Vertex AI. The model is the long-awaited successor to Gemini 3.5 Flash — delayed past the June Sundar Pichai promised at Google I/O on May 19, generating what one account described as an audible groan from developers when the model did not launch that day. Nine days remained in the month when Pichai made that promise. Today is the day it shipped.
The capability story is the most important starting point. Gemini 2.5 Pro Deep Think has a 2-million-token context window — double the 1-million-token window that Claude Opus 4.8 and GPT-5.5 share and the longest context of any generally available frontier model. For enterprises processing large codebases, lengthy legal documents, regulatory filings spanning hundreds of pages, multi-quarter financial analyses or any workflow requiring sustained reasoning across very large input contexts, 2 million tokens is the capability that changes what is automatable. Tasks that previously required document segmentation, retrieval augmentation or multi-pass summarisation can now be processed in a single Gemini 2.5 Pro Deep Think context — eliminating the retrieval overhead, the segmentation engineering and the consistency risk that multi-pass approaches introduce.
The Deep Think reasoning mode is the second architectural capability that distinguishes Gemini 2.5 Pro from the Gemini 3.5 Flash that became Google's default product across all enterprise surfaces last week. Deep Think is Google's equivalent of extended thinking or chain-of-thought reasoning — a mode in which the model performs explicit, multi-step reasoning before producing its final output, trading latency for accuracy on hard problems. Google positions Deep Think for complex mathematical reasoning, difficult logical inference and multi-step scientific problem-solving — the class of enterprise workflows where reasoning accuracy matters more than response speed and where the prior generation of models produced outputs that required significant human verification.
Pricing at $15 per million input tokens and $60 per million output tokens puts Gemini 2.5 Pro Deep Think at the top of the generally available frontier model pricing table. The comparison matrix as of June 23: Gemini 2.5 Pro Deep Think at $15/$60; Fable 5 at $10/$50 (usage credits); Claude Opus 4.8 at $5/$25; GPT-5.5 at $5/$30; Gemini 3.5 Flash at $1.50/$9. The addition of Gemini 2.5 Pro Deep Think to the top of the pricing ladder formally creates a five-tier frontier model market where each tier has distinct capability, latency and cost characteristics that enterprise architecture teams must map against their specific workload requirements.
The Fable 5 billing change that took effect at midnight is the event that makes today particularly consequential for Anthropic enterprise customers. Fable 5 moved from free subscription inclusion to usage credits at $10/$50 per million tokens — double the price of Claude Opus 4.8. The complication is that the 13-day free trial window that Anthropic promised on June 9 included six days when the model was offline due to the US government export control directive. Subscribers who were promised free access through June 22 received approximately 4-5 days of actual access. Anthropic has not announced an extension of the complimentary window as of this morning, and the subscription page on claude.ai still shows the June 22 expiration. The result is that Fable 5 moves to the most expensive generally available tier in the frontier model market — at $10/$50 — without the validation period that most enterprise customers expected to use for production readiness testing.
The Fable 5 pricing context matters for enterprise procurement because it establishes Fable 5 as the frontier model most appropriate for the specific workloads where its capability differential over Opus 4.8 justifies a 2x price premium. Based on available benchmark data — 65.3 percent on DRACO versus Opus 4.8's score below that level — the Fable 5 capability premium is real but not as large as its pricing premium. Enterprise teams that needed the free trial window to validate whether Fable 5's capability justifies $10/$50 pricing have lost that window to the shutdown. The practical recommendation for enterprise teams as of today is to evaluate Fable 5 for a specific narrow category of workflows where its capability differentiates and the cost is justified — and default to Opus 4.8 at $5/$25 for the broader workload portfolio until production validation data is available.
The OpenRouter Fusion DRACO benchmark data is the empirical validation of the multi-model architecture that Legacies Techno and others have been recommending since the Chinese open-weight models we covered in May changed the cost geography of the market. OpenRouter's Fusion tool — which runs prompts across multiple models simultaneously and synthesises their outputs into a single response — produces results that should prompt every enterprise AI architect to update their single-model design assumptions. A panel combining Fable 5 and GPT-5.5 scored 69 percent on DRACO — above Fable 5 alone at 65.3 percent and above every individual model. More consequentially for enterprise cost architecture, a budget panel combining Gemini 3 Flash, Kimi K2.6 and DeepSeek V4 Pro scored 64.7 percent — within one percentage point of Fable 5 alone and outperforming both GPT-5.5 and Claude Opus 4.8 individually — at roughly half the cost of any single frontier model.
That 64.7 percent budget panel score is the most important enterprise AI cost benchmark published in June. It validates, empirically and with a published methodology, the multi-model routing architecture that the cost geography of the market has been pointing toward all year. A three-model budget panel — Gemini 3 Flash at $0.075/$0.30 per million tokens, Kimi K2.6 at $0.16/$0.60, DeepSeek V4 Pro at $0.55/$2.19 — achieves near-Fable-5 performance on the DRACO benchmark at a blended cost that is a fraction of any single frontier model. For enterprise workloads where DRACO-style capability is the relevant benchmark — reasoning, instruction following, multi-step task completion — the budget panel architecture is the cost-optimised alternative to single-model frontier deployment.
The Fusion multi-model synthesis architecture is not yet production-ready for every enterprise use case. The latency overhead of running three models simultaneously and synthesising their outputs adds inference time that synchronous enterprise workflows may not tolerate. The governance architecture for multi-model synthesis — which model's output governs when models disagree, how synthesis conflicts are audited, how data residency requirements apply across three different model providers simultaneously — is more complex than single-model governance. But the performance data is the production requirement, and the performance data says multi-model synthesis at the efficiency tier produces near-frontier performance at sub-frontier cost. The engineering investment to make that architecture production-ready for appropriate workload classes is justified by the cost differential.
The aggregate frontier model market picture as of June 23, 2026 is the clearest and most consequential pricing map the enterprise AI community has seen. At the top: Gemini 2.5 Pro Deep Think at $15/$60, offering the largest context window and the most capable reasoning mode of any generally available model. Second tier: Fable 5 at $10/$50, available on usage credits, offering benchmark performance above Opus 4.8 with governance complexity from the shutdown and the 30-day data retention requirement for non-Enterprise plans. Third tier: Claude Opus 4.8 at $5/$25 and GPT-5.5 at $5/$30, the current production frontier standard for the majority of complex enterprise workloads. Fourth tier: Gemini 3.5 Flash at $1.50/$9, offering above-Opus terminal benchmark performance at one-third the price. Fifth tier: Chinese open-weight models at $0.16-$2.19 per million output, offering competitive performance for appropriate workloads at 10-90x cost savings over frontier closed-source.
The enterprise architecture decision this map requires is explicit multi-tier routing: a governance-controlled routing layer that assigns each workload to the model tier whose capability profile meets the workload's quality requirements at the lowest cost that meets those requirements. The specific routing decision for each workload class — which benchmark metrics matter, what quality floor is required, what latency the workflow tolerates, what data residency rules apply — is the enterprise AI architecture work that most organisations have been deferring in favour of simpler single-model deployment. The June 23 market map makes that deferral increasingly expensive.
At Legacies Techno, the June 23 frontier model market update produces specific and immediate changes to the architecture recommendations our three practice areas make to enterprise clients. Our AI-Powered Platforms practice has been building towards multi-tier model routing architecture throughout 2026. Gemini 2.5 Pro Deep Think's addition to the top of the pricing table provides the large-context, deep-reasoning model that has been missing from the efficiency-tier architecture — a tier-1 option for the specific enterprise workflows that require 2-million-token context or Deep Think reasoning capability, distinguishable from the Opus/GPT-5.5 tier-2 that handles the majority of complex enterprise work.
Our Enterprise Software Development practice is specifically evaluating Gemini 2.5 Pro Deep Think for the enterprise software engineering workflows that benefit most from the 2-million-token context window — specifically the complete codebase analysis, legacy system documentation review and cross-repository dependency mapping that exceed the 1-million-token windows of Opus 4.8 and GPT-5.5. For engineering workflows where the entire relevant codebase fits within the context window, the elimination of retrieval augmentation overhead is a significant engineering simplification and a reliability improvement.
Our Smart Automation practice is tracking the OpenRouter Fusion DRACO data with the most immediate interest. The budget panel's 64.7 percent DRACO score at sub-frontier cost is the performance-per-dollar benchmark that validates the multi-model automation workflow architecture for high-volume, lower-complexity enterprise automation. For the document processing, classification, extraction and reporting automation workflows our practice deploys at scale, the cost economics of a validated budget panel approach versus single-model frontier deployment produces an ROI that compounds dramatically at the volume these deployments process.
Three events, one morning. The frontier model market restructured overnight. Every enterprise AI architecture team has new inputs that require assessment before the next deployment decision.
Key Highlights
- Gemini 2.5 Pro Deep Think launched June 22-23, 2026 on the Gemini API, Google AI Studio and Vertex AI — Google's most capable generally available model, featuring a 2-million-token context window (the largest of any GA frontier model), a dedicated Deep Think multi-step reasoning mode, and pricing at $15 per million input tokens and $60 per million output tokens.
- The 2-million-token context window doubles the 1-million-token windows of Claude Opus 4.8 and GPT-5.5 — enabling complete codebase analysis, full regulatory filing processing, multi-quarter financial analysis and other long-context enterprise workflows in a single context without retrieval augmentation or document segmentation.
- Fable 5's free trial window expired at midnight June 22-23, moving to usage-credit billing at $10 per million input tokens and $50 per million output tokens — the highest pricing in the frontier model market, double the cost of Claude Opus 4.8. Subscribers effectively received 4-5 days of access instead of the advertised 13 days due to the June 12-18 government shutdown.
- OpenRouter Fusion DRACO benchmark data shows: a Fable 5 + GPT-5.5 panel scored 69 percent; Fable 5 alone scored 65.3 percent; a budget panel of Gemini 3 Flash, Kimi K2.6 and DeepSeek V4 Pro scored 64.7 percent — within one point of Fable 5 alone and above GPT-5.5 and Opus 4.8 individually, at roughly half the cost of any single frontier model.
- The five-tier frontier model market as of June 23: Gemini 2.5 Pro Deep Think ($15/$60), Fable 5 ($10/$50, usage credits), Claude Opus 4.8 / GPT-5.5 ($5/$25-$30), Gemini 3.5 Flash ($1.50/$9), Chinese open-weight tier ($0.16-$2.19 per million output). Each tier has distinct capability, latency and cost characteristics requiring explicit workload-tier mapping.
- Gemini 2.5 Pro Deep Think's release completes Google's response to the capability gap created by Fable 5's launch — and arrives while Anthropic's most capable models are either under government restriction (Mythos 5) or newly moved to the highest pricing tier (Fable 5). Google has timed its most capable release to land at Anthropic's most commercially complex moment.
- Anthropic has not announced an extension of the Fable 5 free trial window, despite the 6-day shutdown reducing effective subscriber access from 13 days to approximately 4-5 days. Enterprise teams that needed the validation period for production readiness testing have lost it without recourse as of this morning.
- The Gemini 2.5 Pro Deep Think 30-day data retention requirement for non-Enterprise Vertex AI plans creates a GDPR conflict for EU enterprise users that Anthropic faces with Fable 5 as well — the EU AI Act's data minimisation requirements may conflict with mandatory data retention policies that both frontier labs are implementing for their most capable models.
Why This Matters
- The five-tier pricing structure that exists in the frontier model market as of June 23 is the enterprise AI cost architecture mandate that most organisations have been avoiding making explicit. A market with five distinct pricing tiers between $0.16 and $60 per million output tokens is a market that rewards deliberate multi-tier routing architecture and penalises default-to-frontier-tier deployment. The enterprise that routes all workloads to Fable 5 at $10/$50 is paying 375 times more per output token than a Chinese open-weight alternative for workloads where the alternative's capability is sufficient. That multiplier compounds at enterprise workload volumes into AI infrastructure costs that dwarf what deliberate routing architecture would produce.
- Gemini 2.5 Pro Deep Think's 2-million-token context window is the capability that unlocks a specific class of enterprise workflow that no prior generally available model could address. The complete codebase analysis — where the full dependency graph, all relevant modules, and the complete historical context of a large software system need to be present in the reasoning context simultaneously — has required multi-pass approaches with consistency limitations. Deep Think at 2 million tokens processes it in a single context. The engineering simplification and reliability improvement are both significant. Enterprise teams with large-codebase workflows should evaluate whether the prior multi-pass architecture can be replaced.
- The OpenRouter Fusion DRACO data is the benchmark that every enterprise AI architect should be required to explain in their next model selection recommendation. A budget panel within one DRACO point of Fable 5 at half the cost is not a theoretical argument for multi-model architecture — it is an empirical result with a published methodology. The argument for defaulting to a single frontier model rather than implementing a validated multi-model budget architecture must now account for this data. The burden of proof has shifted.
- The Fable 5 billing situation creates a specific procurement challenge for enterprise Anthropic customers that requires immediate attention. Fable 5 at $10/$50 is the most expensive model in the frontier tier. It has mandatory 30-day data retention for non-Enterprise plans. It was offline for 6 of its 13 free trial days. And it has not yet been available for the extended production readiness testing that most enterprise security and compliance teams require before approving a new model for production data. The rational enterprise response is to maintain Opus 4.8 as the primary production model and evaluate Fable 5 systematically on specific high-value workflows where the capability premium can be quantified — rather than treating the billing change as a signal to broadly adopt the new pricing tier.
Source:
Build Fast With AI — AI News Today June 23, 2026: 15 Biggest Stories Medium / ADI Insights — AI Update Monday June 22, 2026: Gemini 2.5 Pro Deep Think, Fable 5 Billing Cliff Build Fast With AI — AI News Today June 22, 2026: OpenRouter Fusion DRACO Benchmarks, Gemini 2.5 Pro
Author
Janani Sathyamurthy
RELATED NEWS
SEE ALLSEE ALL
Apple's Last Act and Its Biggest AI Bet: What WWDC 2026, Siri AI and iOS 27 Mean for Every Enterprise in Apple's Ecosystem

The Most Capable Model Ever Released and a $965 Billion Valuation: What Claude Opus 4.8 and Anthropic's $65B Raise Mean for Every Enterprise Building on AI
What OpenAI Actually Shipped in May and Where the Frontier Model Market Stands Heading Into June
CONTACT
LET'S ENGINEER THE FUTURE — TOGETHER
.png)
.
.
/
.png)
Whether you're scaling a digital product, modernizing operations, or building from the ground up — Legacies Techno is your partner in crafting intelligent, enterprise-grade solutions that create lasting impact.
GET IN TOUCHGET IN TOUCH